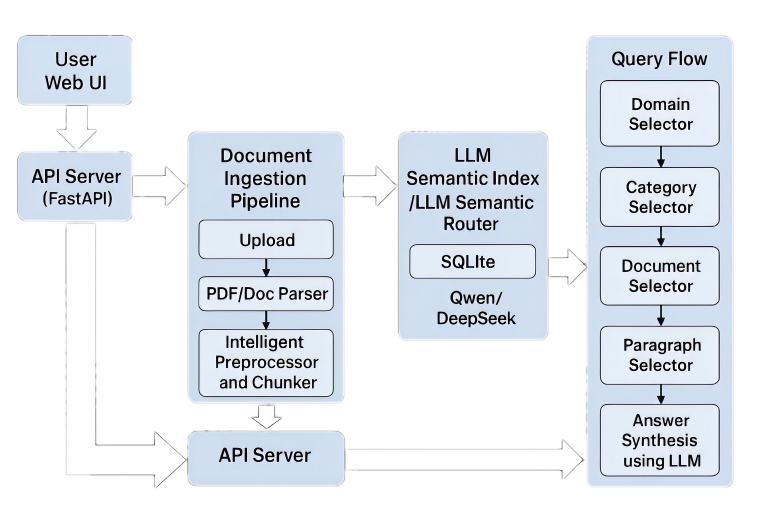
创新性的精准RAG引擎 99%准确率的RAG技术 LibRAG 是一款面向推理型 RAG(Reasoning-Augmented Retrieval)的新一代智能内容召回引擎。它不依赖向量数据库,也无需构建任何词嵌入模型,而是让大语言模型利用自身的深层语义理解与推理能力,直接从文档中定位问题真正相关的内容。通过独特的多级语义索引结构,LibRAG 能够精准理解用户意图、跨文档串联信息、处理复杂逻辑链路,让检索不再是“查相似”,而变成“找答案”。无论是政策制度、技术文档、专业报告还是复杂业务知识,都能在秒级得到高精度、可解释、可审计的回答。 免费试用 LibRAG设计理念 如何从海量文档中精准高效地找到所需知识,是每个企业与个人面临的挑战。传统的RAG捡索通过将全部文本“暴力”切片并向量化,在巨大的高维空间中进行语义相似度匹配。这种方法本质上是一种计算上的“捷径”,最后造成语义失真的结果,就如同将书籍打碎成沙,虽能快速匹配,却失去了知识的脉络与语境。LibRAG的设计灵感源于传统的档案管理学科智慧。我们相信,真正的智能检索不应是关键词的“大海捞针”,而应像一位经验丰富的档案管理员,能够理解知识的体系、关联与上下文,从而为您提供最精准的答案。 LibRAG的优异特性与设计 准确率 > 99% 基于深度语义推理,实现接近人工判断的精准段落召回 召回率 > 95% 智能覆盖几乎所有相关段落,确保召回内容全面不遗漏 秒级响应 响应时间可控,实时输出最优解答 真正理解用户意图 利用语言模型的语义推理能力,精准还原用户问题本质 不依赖词嵌入 不依赖任何嵌入模型,部署轻量且结果稳定 无向量设计 摒弃向量召回误差,直接以逻辑推理锁定最相关内容 行业应用 金融业 合规解读授信审查风控条款 制造业 工艺检索质检定位故障排查 医疗行业 指南解读制度检索质控支持 政企 制度检索政策比对事项指导 免费试用 联系我们,通过我们的云服务环境,获取免费试用配额 点击申请试用